2025-11-02. What is Hyper Automation?
> Back to Main > Back to Blog
According to the Harvard Business Review, "standard automation processes ascend to “hyper” status when they drive cost reductions of 20% to 60% and increases in operational effectiveness of up to 50% for the tasks they target." Great. That is the desired result, the target we should all aim for. But how do we achieve such outstanding results? There are several schools of thought on this subject. The prevailing approach is to pick the proverbial low-hanging fruit first. Here is what that means. If you are a database administrator, you automate your password resets, migrations, and upgrades. If you are a systems admin, you automate your provisioning tasks, and so on. You automate what you control, in other words. The current automation software vendors endorse this approach. They are right in the sense that the results of such task automation will be immediate. They are wrong, however, in another sense— how much of a difference it will make in the long run, to the business. That is why most automation efforts are dead on arrival. Yes, the admin will be excited about the newly acquired automation skills and experience, which will definitely make his resume stand out. But when it is time to write the check, the first question that pops into the manager's head is "what is in it for me?" and the most common answer is "nothing".
The doctrine we believe in is based on the first and second laws of automation.
Here they are (in their Yoda interpretation):
1. The single determining criterion of success is that the object of automation has to disappear.
2. The object and the subject of automation cannot be the same (or, rather, "you can't automate over yourself").
To paraphrase the laws, the point of automation isn't to accommodate the administrators in executing their daily routine, but to extricate them from it entirely as the single most expensive, slowest, error-prone, and unscalable link in the IT services delivery chain. Unlike conventional automation, hyper automation doesn't help administrators. It replaces them to benefit the business itself.
From a traditional standpoint, if a team of database administrators increased their output, then the automation effort was a wild success. That is wrong; it is a failure. Even if your admins doubled their production, the ROI for the business owner is still too low to justify the cost of conventional open-loop automation. That is because an admin's best is still a human's best. Granted, the human IT help sufficed on-prem, where hardware was physical. An average on-prem IT shop had no more than a hundred database instances in a single data center. But not anymore —not in the cloud. The technology became too labor-intensive, too complex, and especially too fluid for a person to keep up with. The fact that 80% of current cloud services lack coherent documentation is proof of that, even the cloud software and services vendors refuse to waste their time on something as fleeting. Here is the bottom line. We have to step back and let the technology manage itself.
Similia similibus curentur (or "treating like with the like").
But all of this has been academic. How do you hyper automate, in practice? That is very simple. To hyper automate a process means to make it disappear. No less. Let's use an analogy. Imagine you live in the past and you have a water well in your backyard.
This one:

A water well
Imagine this is how you get water every day, by drawing a bucket at a time. Imagine you have salesmen enticing you with products. You buy a bigger bucket from one salesman. Now you may draw slightly more water. Another one sells you an electric motor so you won't have to rotate the handle every time you are thirsty (this is all of the autonomous or self-managing database offerings I am alluding to). But at the end of the day, you still don't have a distributed water system with pressure control, fluoridization, and fifteen full-time epidemiologists on payroll. Like this one:

A distributed water system
All you have is a hole in the ground. It doesn't matter how many accessories or good luck charms you attach to it. A hole is a hole. It still benefits you, and you alone, and you still have to get up and walk out to the backyard to get a glass of stale water in the middle of the night. That is the difference between automation and hyper automation. The first helps a person draw a bigger bucket from a well. The second makes the entire well disappear. You don't believe me? Then, when was the last time you even saw a water well? Today, we will do exactly that. We will make a process - poof! - disappear. Here is the technology that will help us achieve that.
- ITIL (Information Technology Infrastructure Library)
- Ansible Collection for ServiceNow ITSM (Information Technology Service Management)
- Ansible Core
- Various vendor utilities. A utility, in this context, is a tool or software that performs a vendor-specific step. For example, Oracle provides its own utility to change certificates or passwords, while AWS or GCP uses a different one. In an omnivendor enterprise automation, utilities play a minor role and are called only when necessary, though no automation can work without them. For example, in this demo, only 5% of the automation code is vendor-specific (AWS, Azure, GCP, or OCI).
Here is the solution's flowchart.
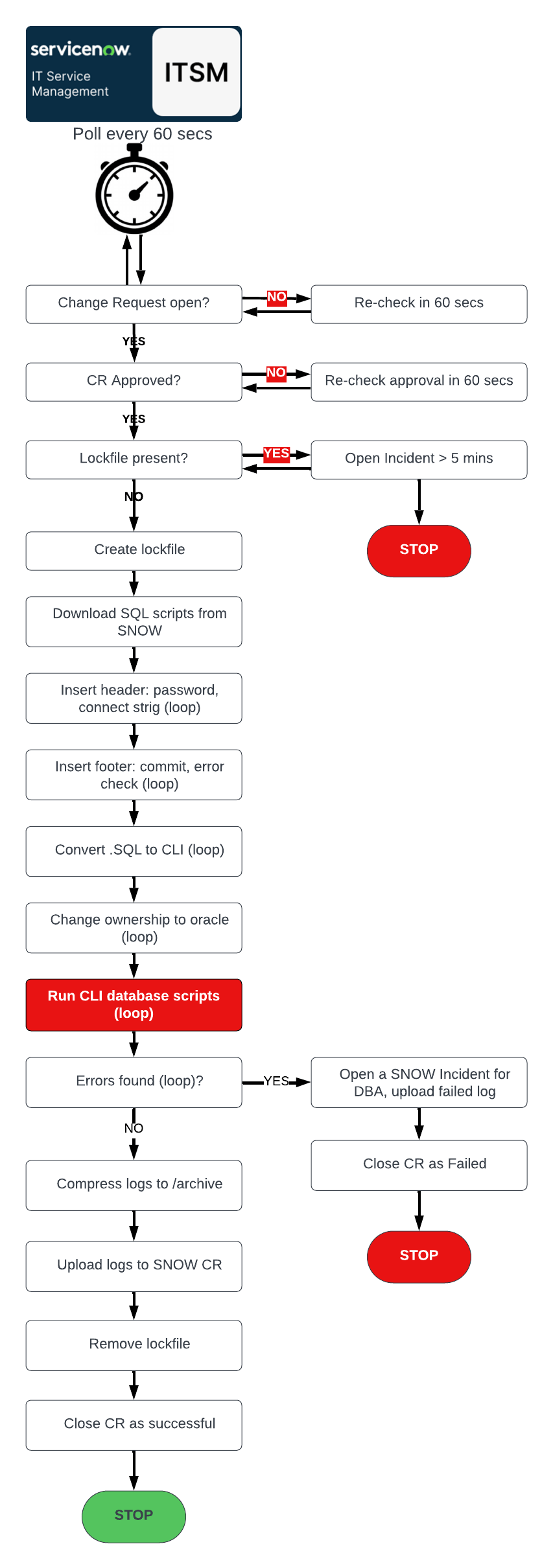
Hyper automation workflow for this demo
You don't have to follow the entire process here. What is important is to understand how we make the process disappear. There are only two steps here:
1. Define the event that triggers the process—whether it's an emergency password reset (as in this demo), a DC migration, an upgrade, or a lower environment refresh.
2. Write the automation code that will execute the triggered process unattended, without any human intervention. Connect the automated flowcharts so they can call each other, open/close/assign incidents and change requests, execute them in real time via an API, test the implementation, and so on.
That is all. The technology part—what tool, vendor, or cloud product the subtasks run in—is almost immaterial. What matters is that the process is entirely automated, top to bottom. If a human is needed anywhere along the loop—even to review an emailed automation summary the following day—the automation is open-loop and incomplete. All possible outcomes and error codes must be addressed before execution, with rollback functionality built in. All vendor best practices have to be embedded in the workflows. Only then will the process disappear from the manager's perspective. Now, let's get on with the demo. Here is what we are up against. This is the inventory.
- AWS - 2,488 instances (RDS Oracle, MySQL, PostgreSQL, MariaDB)
- Oracle OCI - 2,512 instances (Autonomous database, Exadata, Oracle RDBMS, NoSQL)
- Google GCP - 2,498 instances (Spanner, AlloyDB, CloudSQL, Bare Metal)
- Azure - 2,552 instances (MySQL, db SQL, Cosmos, SQL Server)
This is an actual inventory from one of the major US banking clients. There is a 1-in-5 chance you have their credit card in your wallet right now. Today, we are performing an enterprise-wide emergency password rotation. We use an Ansible ten-node automation cluster, each handling a subset of 1,000 instances (10,000 total). The passwords are stored in the Vault. First, we will assign the incident and its linked change requests to an actual person. Then we will monitor a hyper-automation module executing the same tasks in the same change requests to resolve the same incident. I wrote "monitor" because hyper automation starts and does everything on its own, unattended; all we can do is watch it work. Let's cut to the chase. Here is the human scorecard. Just a couple of basic KPI's on this incident.
Enterprise omni-vendor (AWS, Oracle OCI, Azure and Google) emergency 10,000 passwords rotation.
| Person | Hyper Automation | |
| Time spent | 34 years (projected) | 2 hours |
| Cost | $19,200,000 | $0 |
| Error rate | 4% | 0.001% |
| Scalability | -4 (we had to hire additional help) | +1,000 (add Ansible control nodes as needed) |
That is the difference. 34 years vs 2 hours. 19 million dollars vs 0.
The following is a 30-minute video capture of the demo in two parts, with comments.
Part 1 of 2. Introduction to hyper automation of the life cycle of an IT change.
Part 2 of 2. The hyper automation demo: Enterprise omni-vendor (AWS, Oracle OCI, Azure and Google) emergency 10,000 passwords rotation.